
Concluding Remarks
This is complicated stuff. We are seeing some of the best of modern science (genetic sequencing, Moderna, J&J) and some of the worst (Neil Fergusons’s Imperial College epidemiological model garbage coding) on display at the same time. As said before, analogies to ‘climate science’ are legion. As a simple coding example, naive infectious rate R0 is both an input and an output in all epidemiological models depending on personal behaviors. (Naives, self-distancings). BIG math model PROBLEMs unsolvable except by beliefs.
Wuhan Virus Vaccines - Maybe
amwassil
(Michael - When reality fails to meet expectations, the problem is not reality.)
#1
cooked
(David Cooke)
#2
Complicated schmomplicated. The mortality rate is so low that I just don’t care about Covid.
“Flattening the curve” - how about flattening the obesity curve and all the rest that have built up since 50 years? Gates won’t earn a penny from me.
IdesOfMarch
(Ideom)
#3
Slanted political blogs aren’t usually honest discussion, especially when they make mountains out of molehills. The infectious rate of the new coronavirus really isn’t much in doubt. It is not correct to say it’s (only) a matter of belief. Pointing to the mentioned shortcomings in the Imperial College’s code is like complaining about the color of a politician’s hair - will it really make a difference? In this case it definitely does not.
ElmosUzi
(Elmo)
#4
One has to laugh at the “This is complicated stuff,” remark. Blogs like that are often aimed at misdirection - in this case focusing on something that really does not matter, it has nothing to do with “lockdown or not.” Let these bloggers rewrite the code to their satisfaction in the matters they refer to, and it won’t change a thing - a gov’t viewing the new results would make the same decisions.
Worrying about “different results given identical inputs” is really just a concocted point of argument, in this case. Inputs would not be identical anyway (there are myriad things to consider, and it would be ludicrous to act like there is only one input), plus there is considerable uncertainty about the probabilities that such models use, and the output range is so large as to render such concerns meaningless. A lack of exact reproducibility does not mean the model is any less correct - it’s a stochastic model. We are talking about varying outcomes under different conditions.
In the United States, the Centers for Disease Control projected first up to 1.7 million US deaths, then revised it to as many as 2.5 million, bracketing the Imperial College’s “top number” of 2.2 million. This is hardly a secret, nor are they bad estimates for what could happen were nothing done. Given what they had to work with, their numbers are holding up well, much less than an order of magnitude of maximum possible error - considerably less, really, even after only two months. Looking at lower Imperial College ranges for virus suppression strategies, and given the differing conditions present in various countries, some of the Imperial College estimates will end up being spot on. This also would not change (we know this now with 2 more months experience) were the meaningless concerns of the “code critics” in this matter satisfied.
Likewise, with social distancing, the CDC forecasted 100,000 to 240,000 deaths. That is currently certainly in play. The numbers can be refined now - we know much more about the differing population segments’ vulnerability by age, obesity, pre-existing conditions, etc. But would we even change those numbers? For the UK it’s much the same. A comparable (by population) range makes sense, I’m guessing they would just be a little higher in the range or perhaps even exceeding it.
OldDoug
(Doug)
#5
This is what I was talking about in another thread that got closed down.
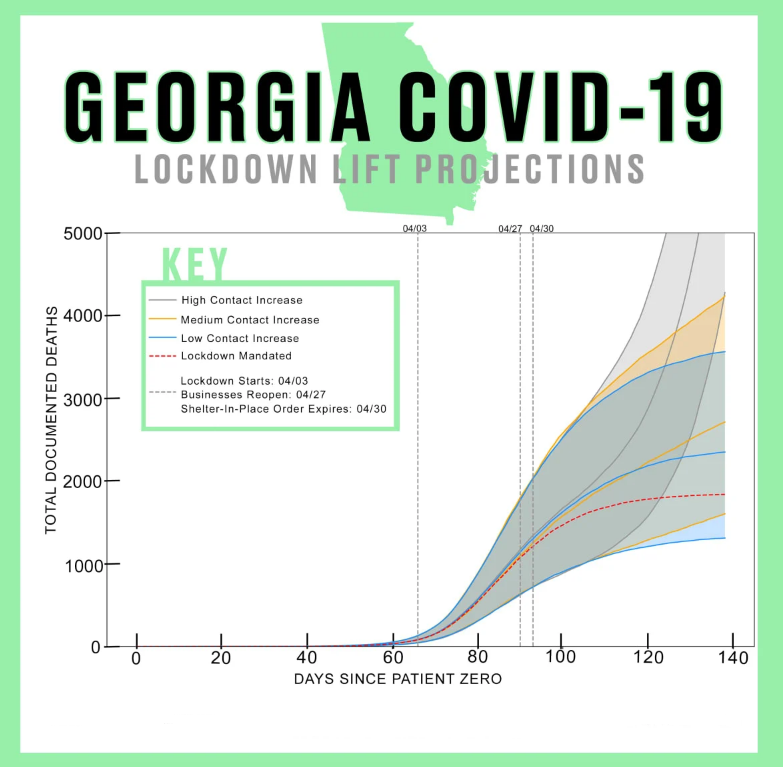
Worrying about some randomness as far as inexact reproducibility is meaningless here - there is necessarily going to be some randomness. Shift the timeline a miniscule amount, or move the inner lines around (would have zero impact), or even shift the outer bands a little (or the probabilities of exceeding them, by so many standard deviations, etc.), and nothing would be changed from a governmental point of view.
I have yet to see a really erroneously (as in wrong by orders of magnitude) high estimate contradicted by real-world results. I googled “highest estimates for Covid-19 deaths,” but didn’t find much.
I thought the above was interesting, but it wasn’t really what I was looking for. I wanted to see “Joe Blow predicts Covid-19 will be 10 times worse than the Spanish Flu” or even “as bad as the Spanish Flu,” but I don’t see such.
The estimates that are wrong by orders of magnitude are on the low side, and often were put forth by people with political axes to grind or other reasons to ignore what was already known and obvious at the time.
One example was the guy who first said ~500 deaths in the U.S. (50,000 for the whole world) and then changed it to 5000 for the U.S. That was with U.S. deaths already being at 1260, and with the numbers of virus cases and deaths taking off like a rocket ship. Exponentially increasing. I figured most 8 year olds could look at the series of numbers we had at the time, and realize that the prediction of 5000 deaths for the U.S. was insanely stupid, i.e. it was easy to see that 5000 would soon be exceeded - figured it would be in 6 or 7 days at that time, and it ended up being 6 days later. There, we have an example that’s obviously wrong by orders of magnitude.
petert
(Peter)
#6
It’s a rather stupid blog, but he’s correct about the Imperial College epidemiological model being garbage (coding). Ferguson has a TERRIBLE track record.
However, only an idiot then concludes that EVERYTHING else wrong as a result.
OldDoug
(Doug)
#7
I’ve seen the code described as old and bloated. No surprise there.
On the “terrible track record” - was this for actual, cut-and-dried predictions, or were these upper (or lower) bounds of stochastic models, like this current matter? To this point, all I’ve seen as specific criticism of the code is the lack of exact reproducibility over multiple runs with the same input. @ElmosUzi says it better than I can, but in this case there seems to be no rational argument that it makes any difference.
The mortality of Covid-19 deaths in New York City, against the city population, is 0.24%. For New York State as a whole, it’s 0.142%. These deaths essentially occurred in 2 months (<100 deaths prior to that). Ferguson’s “worst case” number was 0.664% for the U.S.
So, New York State is already over 1/5 of the way to Ferguson’s “worst case number," and this is 𝑤𝑖𝑡ℎ considerable measures having been taken. Given the facts we are already aware of, what sense does it make to criticize the Imperial College numbers?
In checking on this, I do see that as March 31 the CDC was saying 1.5 million to 2.5 million without social distancing. I presume this means with no virus suppression measures at all.
At that same time, the CDC was saying 100,000 to 240,000 U.S. deaths with social distancing. As of now that seems like a sound analysis. The only way it would be wrong is to be on the low side.
I also saw this:
“𝑇ℎ𝑒 𝑈𝑛𝑖𝑡𝑒𝑑 𝑆𝑡𝑎𝑡𝑒𝑠 𝑖𝑠 ℎ𝑒𝑎𝑑𝑖𝑛𝑔 𝑡𝑜𝑤𝑎𝑟𝑑 𝑚𝑜𝑟𝑒 𝑡ℎ𝑎𝑛 100,000 𝑐𝑜𝑟𝑜𝑛𝑎𝑣𝑖𝑟𝑢𝑠 𝑑𝑒𝑎𝑡ℎ𝑠 𝑏𝑦 𝐽𝑢𝑛𝑒 1, 𝑤𝑖𝑡ℎ 𝑙𝑒𝑎𝑑𝑖𝑛𝑔 𝑚𝑜𝑟𝑡𝑎𝑙𝑖𝑡𝑦 𝑓𝑜𝑟𝑒𝑐𝑎𝑠𝑡𝑠 𝑠𝑡𝑖𝑙𝑙 𝑡𝑟𝑒𝑛𝑑𝑖𝑛𝑔 𝑢𝑝𝑤𝑎𝑟𝑑, 𝐶𝐷𝐶 𝐷𝑖𝑟𝑒𝑐𝑡𝑜𝑟 𝑅𝑜𝑏𝑒𝑟𝑡 𝑅𝑒𝑑𝑓𝑖𝑒𝑙𝑑 𝑡𝑤𝑒𝑒𝑡𝑒𝑑 𝑜𝑛 𝐹𝑟𝑖𝑑𝑎𝑦.”
Is this big news now, considering that the CDC was saying “likely over 100,000” a month and a half ago? And considering that the U.S. ‘only’ has 88,600+ deaths now? 
EZB
(Ethan)
#8
The largest numbers are likely correct. Social distancing changes the duration. If you keep the duration of statistic gathering small, the number of deaths will be less with social distancing, but it doesn’t capture the whole period of infection
OldDoug
(Doug)
#9
Ethan, I was looking at New York state compared with Georgia; even if we freeze NY’s numbers right now, GA getting to the same deaths as percentage of population would mean 9 to 10 times as many deaths as GA has right now.
If the duration is stretched out long enough, then eventually a vaccine or really effective antiviral medicine could affect things. If we don’t get that far - and we may well not - then I’d expect the more-vulnerable people in a given area to have the same experiences as those where the virus is much more now established.
A relatively high portion of elderly people and - as a proxy for several co-morbidities - a relatively high obesity rate would seem to me to predispose a region to more deaths.
We don’t really have a ‘control’ area for social-distancing, to see how the effects differ. Sweden goes a little in that direction, but not enough to really prove anything. If there is a “train wreck” out there, waiting to happen, I’m looking at Brasil. While some measures have been taken, they’re short of what most countries do, and the president is a ‘virus denier’ to a wacky extent.